データ分析
データ型と欠損値
分析用のデータフレーム作成
def func1(df):
result = []
for i in range(len(df.columns)):
col_i = df.iloc[:,i]
dtype = str(df.dtypes.iloc[i])
non_null_ratio = 1 - col_i.isnull().sum() / len(df)
result.append([dtype, non_null_ratio])
return pd.DataFrame(result, index = df.columns, columns = ["dtype", "ratio"]すべての列について処理を行うために
for i in range(len(df.columns)):データフレーム中の特定の列(または行)をインデックスで指定するには、以下のようにする。得られるのはSeries型。
df.iloc[:, i] # i列目をすべて指定df.iloc[i] # i行目をすべて指定DataFrameのコンストラクタ。行ラベル、列ラベルはそれぞれ配列としてindex、columnsに渡す。
class pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=None)データの可視化
seabornライブラリを使用する
import seaborn as snsデータの個数の分布を可視化するにはcountplotを使用する。
引数のxには分布を把握したい成分を渡す。
sns.countplot(x="dtype", data=df)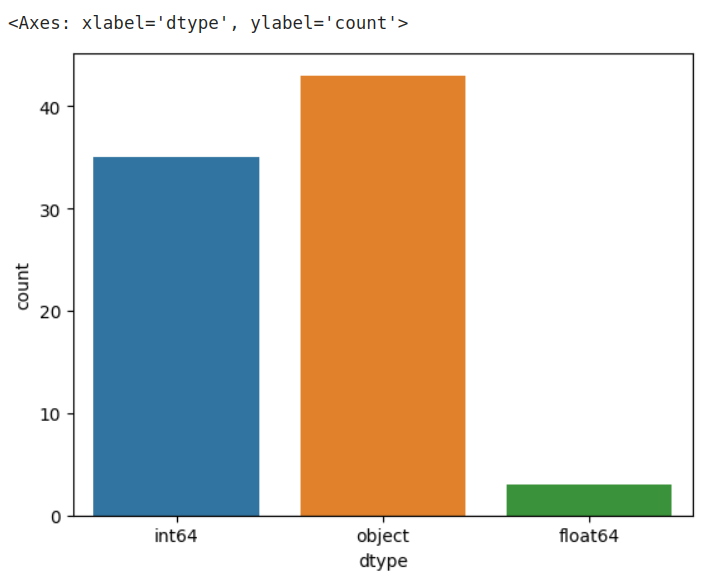
データの分布や統計的特徴を可視化するにはboxplotを使用する。
引数のxにはカテゴリを渡し、引数のyにはプロットしたい値を渡す。
sns.boxplot(x="dtype", y="ratio", data=df)
相関関係
相関係数を計算するにはdf.corr()メソッドを利用して相関係数行列を得る。
今回は、データ型が整数または浮動少数であり欠損値がないパラメータについて計算する。
corrmtx = train_data[list(analysis[(analysis['ratio'] == 1) & (analysis['dtype'] != "object")].index)].corr()データ中の特定の列だけを取り出すには
dataframe[(取り出したいカラム名のリスト)]データフレーム中の特定の条件を満たす要素だけを取り出すには、ブールインデクシングを用いる。
dataframe[(ブール値の行列)]特に複数の条件を合わせたいときは
dataframe[(条件1のブール行列) & (条件2のブール行列)]可視化にはヒートマップを用いる。
plt.figure(figsize=(12,12))
sns.heatmap(corrmtx,square = True)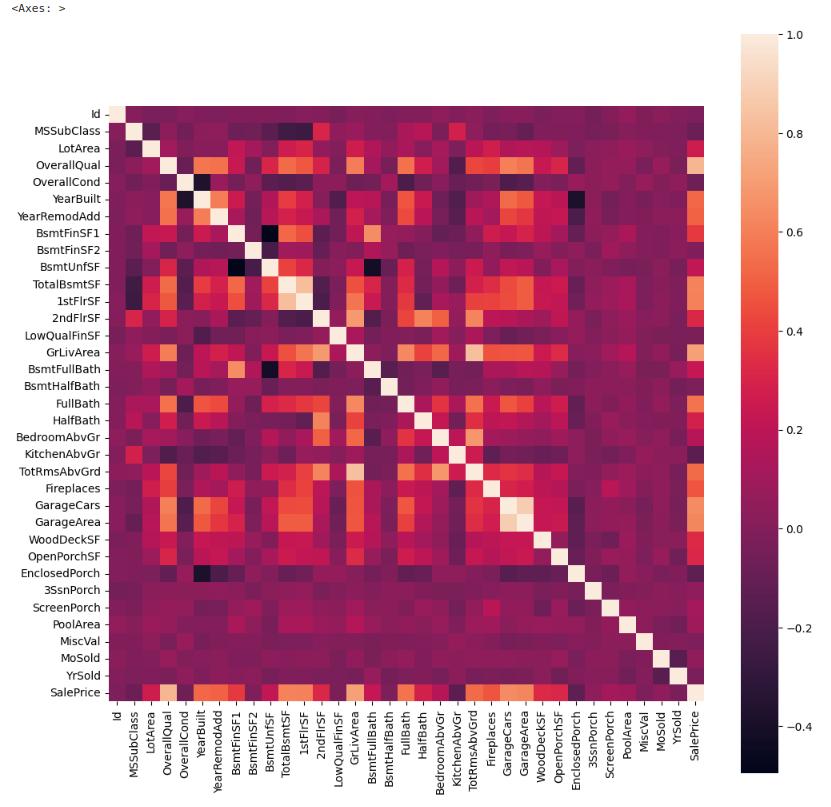
知りたいのはSalePriceとの相関関係なのでソートをかける
order = list(corrmtx['SalePrice'].sort_values(ascending=False).index)
plt.figure(figsize=(12,12))
sns.heatmap(corrmtx[order], square=True)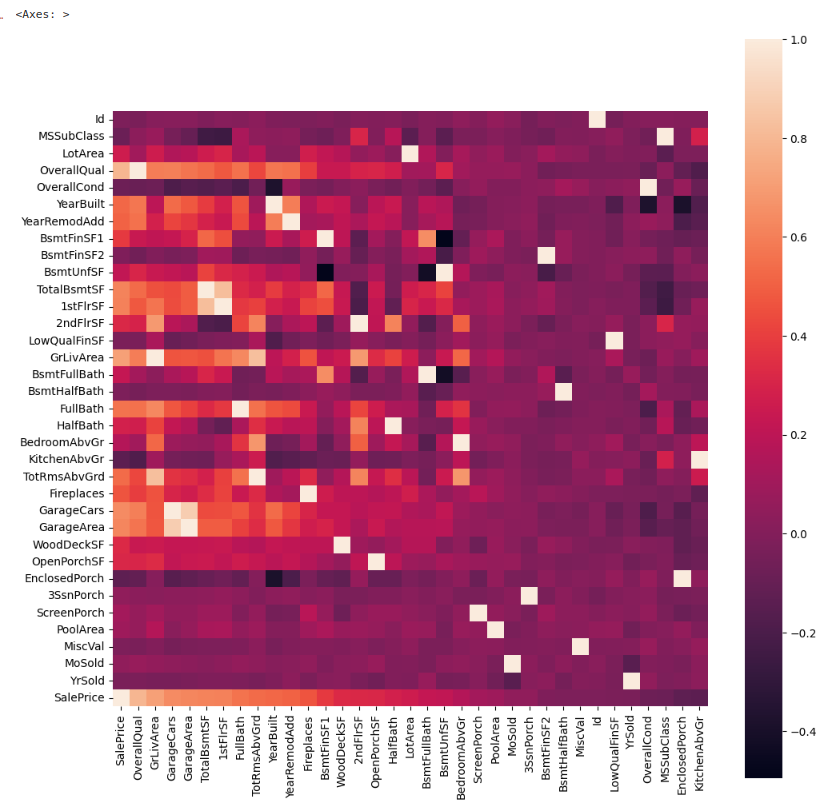
すると最初の21個のパラメータが相関を持っていそうだとわかる。
head(n)を使用すると先頭からn行を取り出すことができる。
order = list(corrmtx['SalePrice'].sort_values(ascending=False).head(21).index)
plt.figure(figsize=(12,12))
sns.heatmap(corrmtx[order], square=True)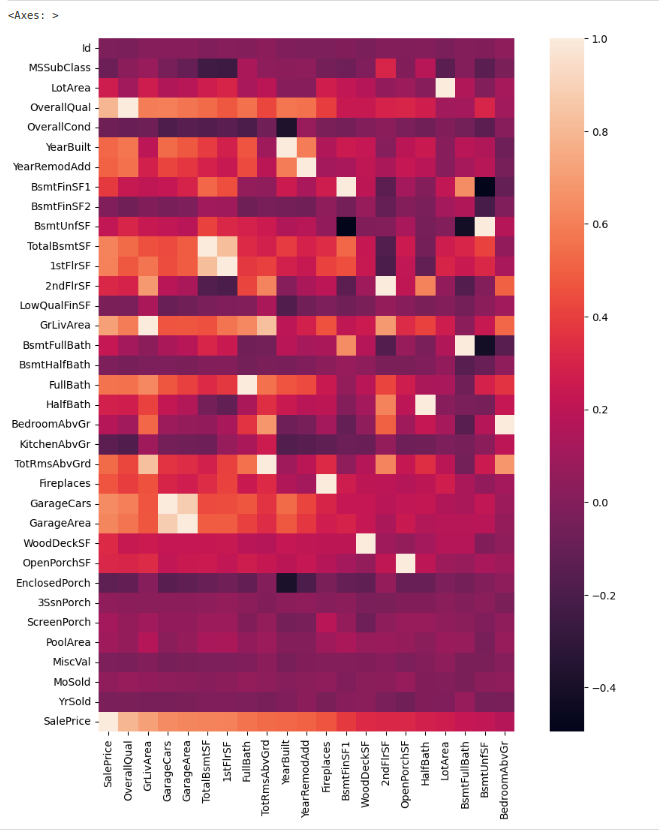
データの分布
分布を調べるにはhistplotを使用する
plt.figure(figsize=(12, 12))
sns.histplot(train_data['SalePrice'], bins=10)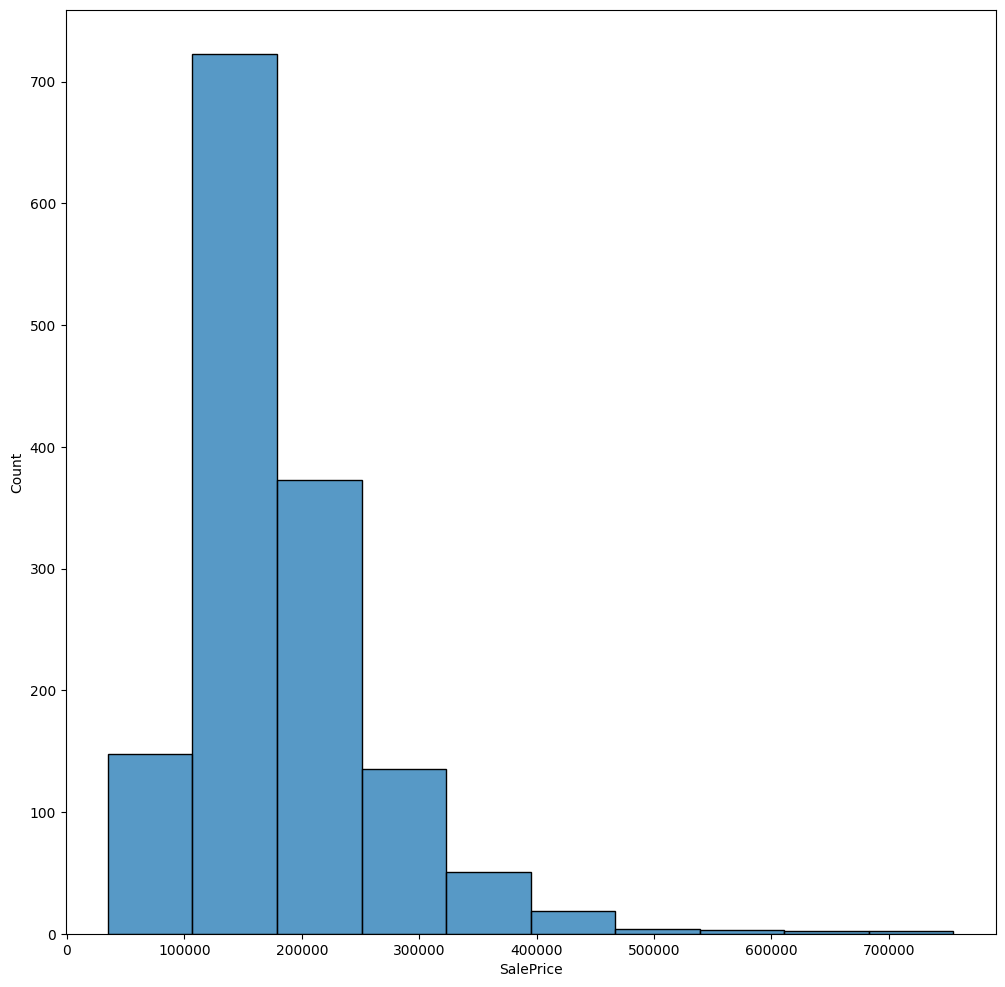
ラベルエンコーディング
カテゴリカルデータは文字列の状態では扱えないので「ラベルエンコーディング」などの手法を用いて数値に変換する必要がある。
ラベルエンコーディングでは、異なるカテゴリには異なる整数値を割り当てる。
例えば、
["犬", "猫", "鳥"]というカテゴリが存在する場合は、
犬 → 0
猫 → 1
鳥 → 2と変換する。
pythonのsklearnライブラリにあるpreprocessing.LabelEncoderを使用する。
le = preprocessing.LabelEncoder()
le.fit(配列の類のもの)
transformed = le.transform(配列の類のもの)分散分析
分散分析とは、異なるグループの平均同士を比較する手法。観測される差異が偶然なのか他のグループに関連しているのかを知ることができる。
例として以下のMSZoningを考える
MSZoning: Identifies the general zoning classification of the sale.
A Agriculture
C Commercial
I IndustrialAのZoningを持つ家の値段を平均するとX円
CのZoningを持つ家の値段を平均するとY円
IのZoningを持つ家の値段を平均するとZ円
だったとする。
「X = Y = Z」となることを仮定(帰無仮設)
計算されるp値が小さいほどこの仮定が成り立たないと言える。
pythonで行う場合はstatmodelsライブラリを用いる。
scipyライブラリも使えるが、より詳しいのはstatmodelsライブラリ。
import scipy as sp
import statsmodels
import statsmodels.api as sm
import statsmodels.formula.api as smf以下は分散分析表を作るための定石パターン
anova_model = smf.ols('目的変数 ~ ' + '説明変数', data=df).fit()
anova_table = sm.stats.anova_lm(anova_model, typ=2)anova_tableの中身は以下のようになっている(PRがp値)

モデル構築
訓練用と確認用でデータセットを分ける
訓練に使ったデータが含まれないデータセットを用意しないと正しい評価ができない。
from sklearn.metrics import log_loss
from sklearn.model_selection import KFold
kf = KFold(n_splits=5, shuffle=True, random_state=71)
tr_idx, va_idx = list(kf.split(X))[0]データセットの分割をいくつ用意するか指定する
今回は5つ用意する。
データセット Xを X1, X2, X3, X4, X5に分割。
kf = KFold(n_splits=5, shuffle=True, random_state=71)list(kf.split(X))[0] = X1(確認用)、X2-X5(訓練用)
list(kf.split(X))[1] = X2(確認用)、X1,X3-X5(訓練用)
...
のようになっているGBDT
GBDTが何かについての概要は以下のサイトが参考になる。
lightgbm
勾配ブースティング木を行うライブラリはいくつがあるが、そのなかでも現在主流なlightgbmを使用する。
import lightgbm as lgbまずは、lgbを使用するためにlgb用のデータフレームに変換する
lgb_train = lgb.Dataset(tr_x, tr_y)
lgb_eval = lgb.Dataset(va_x, va_y)訓練の設定をする。
回帰や分類などのタスク、評価指標などに合わせて調整する。
params = {'objective':'regression', 'seed' : 71, 'verbose' : 0, 'metrics' : 'rmse'}
num_round = 100実際に訓練を行う
model = lgb.train(params, lgb_train, num_boost_round=num_round, valid_names=['train','valid'], valid_sets=[lgb_train, lgb_eval])上記で作成したモデルを用いて予測を行う
va_pred = model.predict(va_x)提出用ファイルの作成
モデルを用いて予想した結果を提出ファイルとして保存する。
submission = pd.read_csv('/kaggle/input/house-prices-advanced-regression-techniques/sample_submission.csv')
submission['SalePrice'] = pred
submission.to_csv('submission.csv', index=False)
コメントを残す