
大学の授業の一環で、CG/CVに関する何かしらの実装をする必要があったので、Stable Diffusionをスクラッチで実装しました。
こちらの動画を参考にしています。
実装したのは以下の部分です。
- Encoder/Decoder (VAE)
- CLIP Encoder
- UNET
- Sampler(繰り返しノイズ除去を行う過程)
Encoder/Decoder
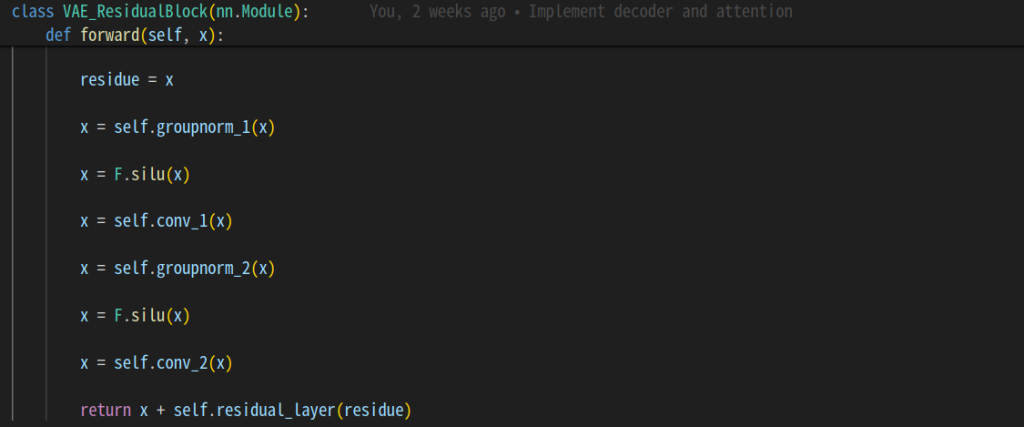
サイズを小さくしながら特徴量を増やしていく過程や、Residual Block、セルフアテンションの実装をしました。
Stable DiffusionではVQ-VAEが使われていますが、今回は単純にVAEを実装しています。
Residual Block
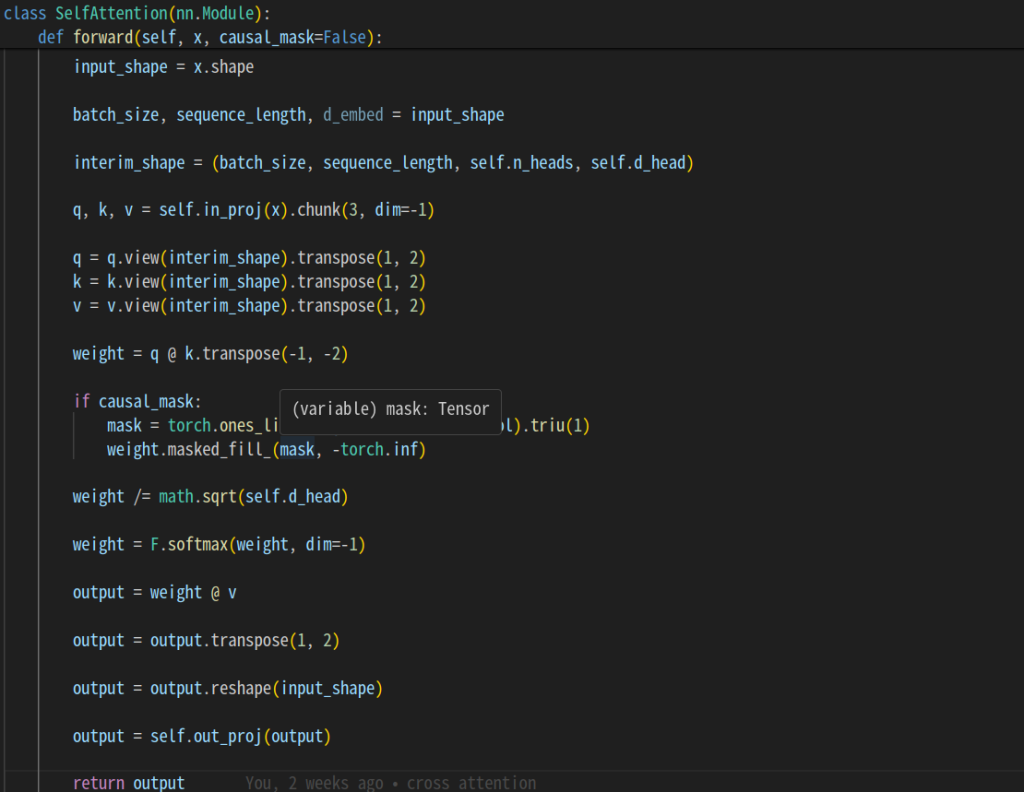
Self Attention
query, key, valueを使ってattentionの論文にある式のまま計算しています。
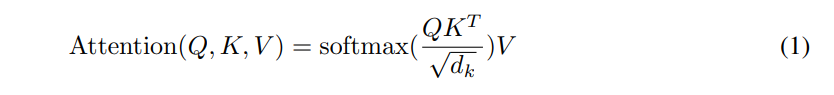
CLIP Encoder
入力されたプロンプトの意味を解釈する処理を行います。
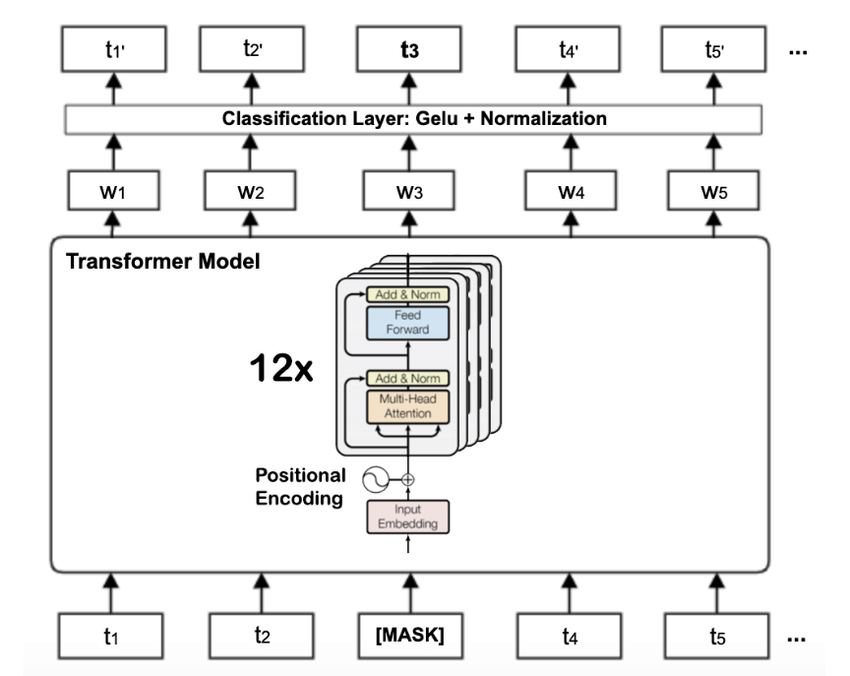
実装はBERTモデルに従っています。
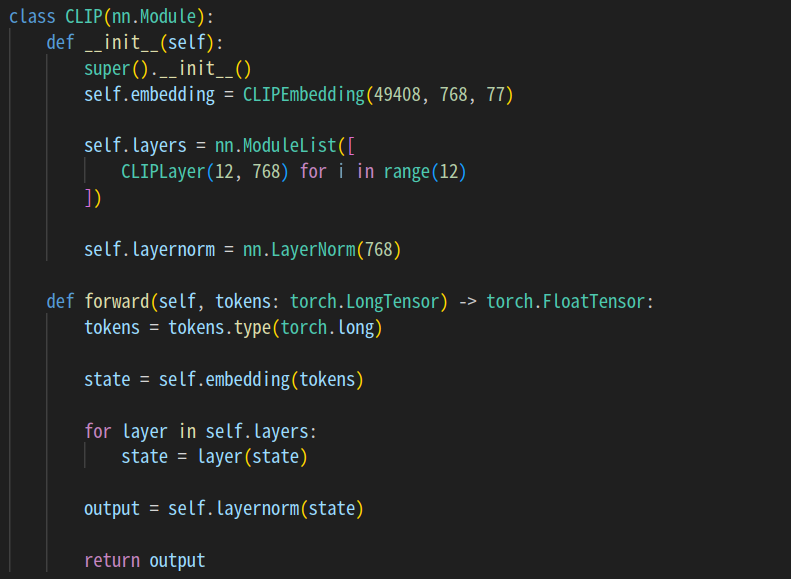
まずは、入力プロンプトの一つ一つの単語をベクトルに変換します。
このときに、positional embedding(positional encoding)として、単語がどの位置にあるかの情報も含めるようにしています。

その後に、12回アテンションを含む処理を繰り返します。
1回の処理はここで定義。
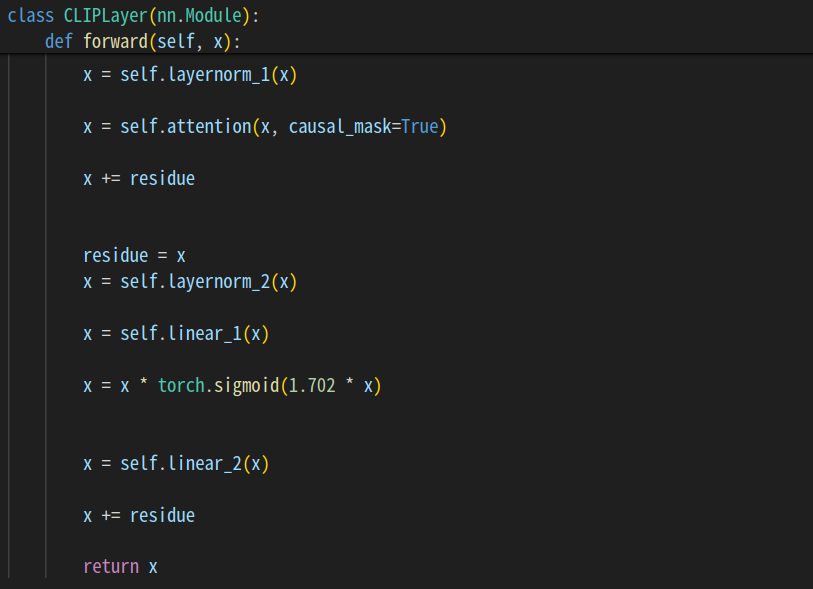
それを12回繰り返します。
UNET
ノイズを除去する処理をします。
stable diffusionの場合は、間でcross attentionを挟んでいます。
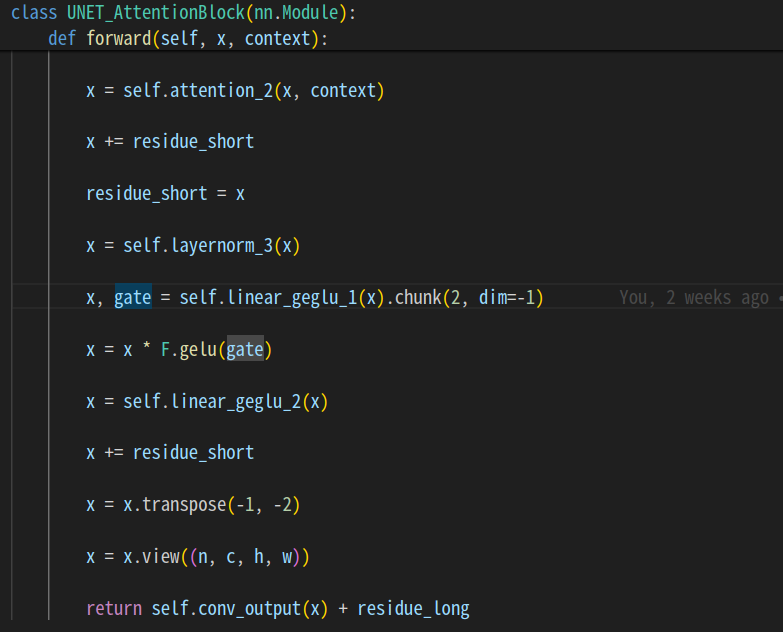
Sampler
DDPMの論文の式に基づいて、時刻と現在の状態から、ノイズを少しだけ除去した状態を予想します。
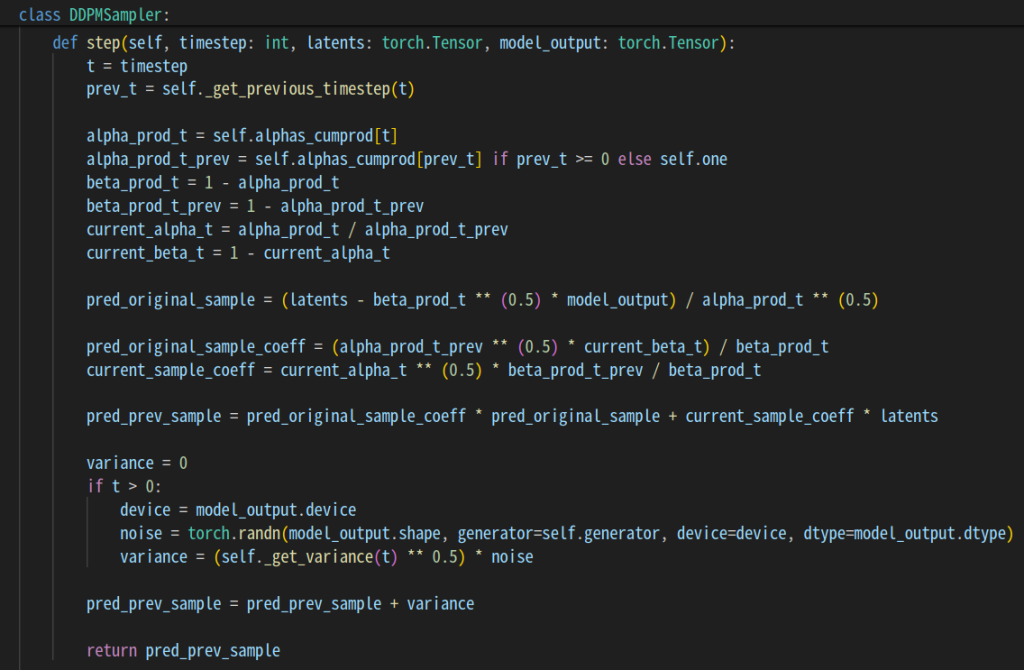
ノイズを少し取り除いた状態の予想は以下のように行っています。
最初の状態を予想
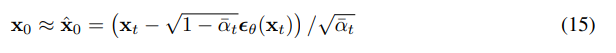
x0と時刻に依存するパラメータを使って、一つ前の状態(ノイズが少し減った状態)を予想
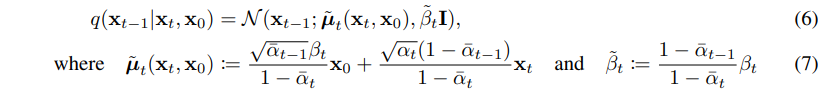
結果
A cat stretching on the floor

Japanese people on the floor ,using laptop ,learning computer science
